'분류 전체보기'에 해당되는 글 171건
-
코딩 몰라도 앱 만드는 시대? 요즘 핫한 '바이브 코딩(Vibe Coding)'2026.03.12
-
!['[수원] 운멜로키친 3호점 후기' 포스트 대표 이미지](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2Fcy1En7%2FdJMcafTa67h%2FAAAAAAAAAAAAAAAAAAAAAHT4pEdlS1WpAH49_8wweVZjZ9QYL1s8fQ8tiOngHDpT%2Fimg.jpg%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1782831599%26allow_ip%3D%26allow_referer%3D%26signature%3DDOjXXrsUNnWe1ALIZeFCqgBbEMQ%253D) [수원] 운멜로키친 3호점 후기2026.03.05 1
[수원] 운멜로키친 3호점 후기2026.03.05 1 -
!['[서울/통인시장] 체부동 잔치집 메뉴 후기' 포스트 대표 이미지](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FwQtBg%2FdJMcadOwQuu%2FAAAAAAAAAAAAAAAAAAAAACuqrTbW8rwjx4-jc_oThmCei17rOvZ22a1YjzOCzmQX%2Fimg.jpg%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1782831599%26allow_ip%3D%26allow_referer%3D%26signature%3D47WGHvqF9SJ1jxMERF1t4DiAMrw%253D) [서울/통인시장] 체부동 잔치집 메뉴 후기2026.03.01
[서울/통인시장] 체부동 잔치집 메뉴 후기2026.03.01 -
!['[여의도] 최우영스시야 초밥 추천 후기' 포스트 대표 이미지](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FcoQ1Sw%2FdJMcai3ncS0%2FAAAAAAAAAAAAAAAAAAAAAMoWB0NsSzPTx6ZxML3mfbTIpg-uDmn-bb72_5NNr0Dl%2Fimg.jpg%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1782831599%26allow_ip%3D%26allow_referer%3D%26signature%3D4i7kb0uo7LciBd%252FPef11b%252FUEN3s%253D) [여의도] 최우영스시야 초밥 추천 후기2026.02.26
[여의도] 최우영스시야 초밥 추천 후기2026.02.26 -
!['[석촌] 태양의 토마토 라멘 영업시간 메뉴 후기' 포스트 대표 이미지](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FbdveDt%2FdJMcaivyCHU%2FAAAAAAAAAAAAAAAAAAAAAPRTgV-ekKEH6L5XoFNsQ-VZMjNM5DBmkbGuefg0I0T4%2Fimg.jpg%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1782831599%26allow_ip%3D%26allow_referer%3D%26signature%3Dw3cQ11MCpD0oHSfFTc%252FJ79tgugM%253D) [석촌] 태양의 토마토 라멘 영업시간 메뉴 후기2026.02.23
[석촌] 태양의 토마토 라멘 영업시간 메뉴 후기2026.02.23 -
!['[모란역] 성남 성원식당 등갈비찜 곤드레밥 영업시간 메뉴' 포스트 대표 이미지](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FFZE13%2FdJMcacouixd%2FAAAAAAAAAAAAAAAAAAAAACRXRvdcNNc_ybEr6XGxaMsL9qJoFJjrAupHdl_lUdiC%2Fimg.jpg%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1782831599%26allow_ip%3D%26allow_referer%3D%26signature%3DJR1z7sCtM%252FekjMoRkD4CUH0vtuQ%253D) [모란역] 성남 성원식당 등갈비찜 곤드레밥 영업시간 메뉴2026.02.14
[모란역] 성남 성원식당 등갈비찜 곤드레밥 영업시간 메뉴2026.02.14 -
오랜만에 블로그 들어와서..2026.02.11 1
-
!['[여의도] 직화 별미볶음집 주차 영업시간 메뉴 내돈내산' 포스트 대표 이미지](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FVIC6s%2FdJMcabb2sPO%2FAAAAAAAAAAAAAAAAAAAAAKe7IkqknbWdweOsGy_AbHaHSjO14ppWor90foQ1QrsY%2Fimg.jpg%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1782831599%26allow_ip%3D%26allow_referer%3D%26signature%3DG4qzJYMLgNR3Emp7rkLPTBEh4QU%253D) [여의도] 직화 별미볶음집 주차 영업시간 메뉴 내돈내산2026.02.11 1
[여의도] 직화 별미볶음집 주차 영업시간 메뉴 내돈내산2026.02.11 1 -
!['[Python] 비지도 학습 - 군집분석' 포스트 대표 이미지](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2Fl3hhG%2Fbtqx2UNgIb0%2FAAAAAAAAAAAAAAAAAAAAAO0Z1evZ-K47K_4TzxctP744_QF5xHgFy5kA8J4hypIy%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1782831599%26allow_ip%3D%26allow_referer%3D%26signature%3DCxZIG4gk7Gv6yB3Avw9rNW2Ez6Y%253D) [Python] 비지도 학습 - 군집분석2019.09.04
[Python] 비지도 학습 - 군집분석2019.09.04 -
!['[Python] openCV 이용한 얼굴인식' 포스트 대표 이미지](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FE5AxC%2Fbtqx1yXqvtC%2FAAAAAAAAAAAAAAAAAAAAAJrLqIuSXTPuG6KTL7pcVQ4zVf1DY2jbds2IRQixDPOd%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1782831599%26allow_ip%3D%26allow_referer%3D%26signature%3DuXbELoSwcQxVSrgC6IYiOJ6T6pM%253D) [Python] openCV 이용한 얼굴인식2019.09.03
[Python] openCV 이용한 얼굴인식2019.09.03
코딩 몰라도 앱 만드는 시대? 요즘 핫한 '바이브 코딩(Vibe Coding)'
안녕하세요!
오늘은 최근 개발 업계와 테크 판을 뜨겁게 달구고 있는 흥미로운 신조어,
'바이브 코딩(Vibe Coding)'에 대해 알아보려고 합니다.
전 테슬라 AI 책임자 안드레아 카파시가 언급하며 화제가 된 이 용어,
도대체 어떤 의미일까요?
1. 바이브 코딩이란?
전통적인 코딩이 프로그래밍 언어(C, Java, Python 등)의 문법을 익혀 한 줄씩 직접 입력하는 방식이었다면,
바이브 코딩은 AI와 대화하며 '느낌(Vibe)'으로 소프트웨어를 만드는 방식을 말합니다.
개발자가 "이런 기능이 있고, 디자인은 이런 느낌인 웹사이트 만들어줘"라고 말하면,
AI가 그 의도(Vibe)를 파악해 코드를 대신 짜주는 것이죠.
2. 핵심은 '언어'가 아니라 '대화'
바이브 코딩의 핵심은 다음 세 가지로 요약할 수 있습니다.
- 자연어 명령: 복잡한 문법 대신 우리가 평소 쓰는 말로 소통합니다.
- 반복적 수정(Iterative): AI가 만든 결과물을 보고 "이 부분은 좀 더 어둡게", "버튼 위치는 왼쪽으로" 같이 피드백을 주며 완성도를 높입니다.
- 결과 중심: 코드가 어떻게 돌아가는지 세세하게 아는 것보다, 내가 원하는 결과물이 빠르게 나오는 것에 집중합니다.
3. 왜 지금 '바이브 코딩'인가?
최근 Cursor(커서), Claude, GPT-4o 같은 AI 툴들이 놀라울 정도로 똑똑해졌기 때문입니다.
이제는 전문 개발자뿐만 아니라 기획자, 디자이너, 심지어 코딩을 전혀 모르는 일반인도
본인이 원하는 툴이나 앱을 몇 분 만에 뚝딱 만들어낼 수 있는 시대가 된 것이죠.
4. '바이브'만으로 충분할까? (주의점)
물론 장점만 있는 건 아닙니다.
디버깅의 어려움: AI가 짠 코드를 이해하지 못하면, 나중에 큰 오류가 생겼을 때 대처하기 힘들 수 있습니다.
유지보수의 한계: 겉보기엔 멀쩡해도 속은 엉망인 '스파게티 코드'가 될 위험도 있죠.
따라서 전문가들은
"기본적인 개념은 공부하되,구현은 AI에게 맡기는 방식"
이 가장 효율적이라고 조언합니다.
이제 코딩은 더 이상 공부해야 할 '장벽'이 아니라,
내 아이디어를 실현해 줄 '도구'가 되었습니다.
다만, 빠르게 발전하는 AI를
좋아해야할지, 걱정해야할지 고민이 되는 요즘입니다.
[수원] 운멜로키친 3호점 후기
영업시간 11:30-21:30
브레이크 타임 15:00-16:30
라스트오더 20:30
수원에 사는 친구를 만나기 위해
퇴근하고 행궁동행
전부터 가보고 싶었던 식당인
운멜로키친
호점도 많고,
각 매장마다 파는 메뉴들도 조금씩 다르다고 한다.

매장은 각 테이블이 넓게 떨어져있어
이야기 하기 좋다.
소개팅하기 좋은 매장 같다.
그리고 트리가 크게 있다보니
크리스마스 분위기 가득!
평일 저녁이다보니
예약하지 않아도 웨이팅 없이 들어왔다.


1호점과 헷갈린 친구를 기다리며
작은 인테리어들을 구경했다.
전부터 먹고 싶었던
상하이 가리비 파스타!
매콤할 수 있어 풍기크레마도
함께 주문했다.
따뜻한 식전 빵도 준다.

이렇게 보다 보니 접시도 이쁘지만,
조명이 사진 찍기 좋은 조명이란 생각을 했다.


상하이 가리비 파스타는 매콤했고, 간이 조금 있는 편이였다.
풍기크레마는 크림맛도 많이 나고 매콤할 때 먹기 좋았다.

집에 돌아가는 길
하늘의 달이 이뻐 찍었다.
PS.
집에 가려다 노트북가방이 없는 것을 깨닫고...
카페갔다.. 네컷 사진 찍은데 까지 다시 뛰어가며..
경찰서까지 가는 상상도 하며..
물건을 잘 챙기자 다짐한 하루였다.
'이모저모 > 식도락' 카테고리의 다른 글
| [서울/통인시장] 체부동 잔치집 메뉴 후기 (0) | 2026.03.01 |
|---|---|
| [여의도] 최우영스시야 초밥 추천 후기 (0) | 2026.02.26 |
| [석촌] 태양의 토마토 라멘 영업시간 메뉴 후기 (0) | 2026.02.23 |
| [모란역] 성남 성원식당 등갈비찜 곤드레밥 영업시간 메뉴 (0) | 2026.02.14 |
| [여의도] 직화 별미볶음집 주차 영업시간 메뉴 내돈내산 (1) | 2026.02.11 |
[서울/통인시장] 체부동 잔치집 메뉴 후기
통인시장
영업시간 08:30-22:30
매달 3번째 일요일 휴무
식사는 10:00-22:30까지
예전에 인왕산 다녀와서
체부동 잔치집 본접에 방문한 적이 있다.
그때 관광객도 많고
30분 정도 웨이팅 후 들어갈 수 있었다.
손님도 많아서 안내가 부족했지만,
가격이 저렴해서 3명이서 메뉴 6개를 시켰던 기억이 있다.
날도 춥고 그때의 맛을 느끼기 위해
경복궁역쪽에 방문한 김에
통인시장점으로 가보았다.

통인 시장 자체가 처음이지만,
늦은 시간 대에 방문하다 보니 시장 문을 많이 닫았다.
다음에는 낮에 와서
시장 구경도 해보고 싶다.

메뉴를 보면, 가격이 정말 싸다.
잔치 국수 하나가 5,000원이다.
늦은 시간이였지만, 외국인 분들도 계시고
혼자 식사하는 분들도 계셨다.



매장 안에는 많은 테이블 좌석이 있다.
혼자 앉는 자리도 있고, 매장 안 화장실도 있다.
화장실을 이용하지 않았지만,
밖에 나가지 않아도 되는 것이 좋은 것 같다.
주방 뒤쪽으로는
좌식형태의 넓은 룸이 있다.

장독대에 김치를 담아준다.
필요한만큼 덜어먹을 수 있는 것이
장점이다.
김치 빛깔을 보고
원산지를 바로 확인했지만,
역시 중국산이였다.

바로 반반 만두(+6,500원)을 주문했다.
10개가 이쁘게 담겨져나왔다.
한입 먹고
이건 만든 만두인가?
라는 생각이 들었다.
만두피가 두껍지 않고,
안에 속 재료 맛이 느껴지며
식감을 느낄 수 있었다.
맛있어서 하나 더 시키려다가
국수를 곱빼기로 시켰기 때문에 참았다.

받자마자 우와
양을 보고 감탄했다.

양이 많고 새콤 고소한 향이
입맛을 돋구었다.

기본적으로 비빔국수에는
잔치국수 육수를 준다.
그래서 따뜻하게 먹을 수 있고,
잔치 국수를 덜어먹기 좋았다.
면이 소면이 아니라 중면이다.
잔치 국수는 멸치 육수에 호박과 김가루 맛이 느껴지며,
면을 씹는 맛이 있다.
잔치 국수는 초고추장 맛이며, 새콤달콤하다.
매운 것을 못 먹는 분한테는 매콤할 수 있을 것 같다.

이렇게 해서 19,500원밖에 나오지 않았다.
이게 시장 물가인가 감탄했는데,
카드 내역을 보니 온누리 상품권 금액으로
결제가 되었다.
이전에 상생 페이백을 신청했고,
10만원 페이백을 받았다.
이 온누리 상품권을 어디에 쓰지 고민을 했는데
체부동 잔치집도 시장에 있어
자동으로 결제가 되었다.
만일 상생페이백을 받아
어디서 써야할지 모르겠다 하시면
시장 내 식당들도 추천합니다.
'이모저모 > 식도락' 카테고리의 다른 글
| [수원] 운멜로키친 3호점 후기 (1) | 2026.03.05 |
|---|---|
| [여의도] 최우영스시야 초밥 추천 후기 (0) | 2026.02.26 |
| [석촌] 태양의 토마토 라멘 영업시간 메뉴 후기 (0) | 2026.02.23 |
| [모란역] 성남 성원식당 등갈비찜 곤드레밥 영업시간 메뉴 (0) | 2026.02.14 |
| [여의도] 직화 별미볶음집 주차 영업시간 메뉴 내돈내산 (1) | 2026.02.11 |
[여의도] 최우영스시야 초밥 추천 후기
영업시간 11:00–21:30
브레이크 타임 15:00-17:00
라스트오더 21:00
초밥을 좋아하는 사람으로써
저렴한 가격에 우동까지 먹을 수 있는
점심 특선을 자주 찾는다.
다만,
회사 근처 초밥집이 별로 없어서 그런지
초밥을 먹고 싶으면 긴 웨이팅 시간을 기다려야해서
많이 포기했던 메뉴이다.
여의도 주변 식당들은
주말에 오픈하는 식당이 거의 없고
더현대나 IFC 몰 내부 식당을 이용해야한다.
맛있고 가성비 좋은 식당을 찾다가 발견한 초밥집을
오늘 소개하려고 한다.
(사실 2번째 방문)


초밥 외에도 사시미 메뉴도 있고,
카이센동, 초밥도 종류별로 판다.
저는 전과 동일하게
모듬초밥 12pcs 로 시켰다.


매장 내부는 1인을 위한 좌석과
테이블 좌석이 나눠져있다.
들어오자마자 오른쪽에는 키오스크가 있다.
포장 주문하는 사람을 위한 키오스크로,
매장에서 먹고 가려면 좌석에 앉아서
테블릿을 통해 주문하면 된다.

정갈하게 나온 모둠초밥
13,000원
여긴 간장이 진하기 때문에
조금만 먹어도 된다.
그리고 와사비는
듬뿍 주기 때문에 걱정이 없다.
저 두께가 사진으로 담기지 않을 것 같지만,
우니와 참치, 연어 등
가격 대비 퀄리티가 너무 좋다.
한입 가득 먹을 수 있어
대식가인 나도 배부르게 먹는다.
주말에도 장사를 하기 때문에
여의도에서 점심이든 저녁이든
초밥이 먹고 싶을 때 방문 추천!
'이모저모 > 식도락' 카테고리의 다른 글
| [수원] 운멜로키친 3호점 후기 (1) | 2026.03.05 |
|---|---|
| [서울/통인시장] 체부동 잔치집 메뉴 후기 (0) | 2026.03.01 |
| [석촌] 태양의 토마토 라멘 영업시간 메뉴 후기 (0) | 2026.02.23 |
| [모란역] 성남 성원식당 등갈비찜 곤드레밥 영업시간 메뉴 (0) | 2026.02.14 |
| [여의도] 직화 별미볶음집 주차 영업시간 메뉴 내돈내산 (1) | 2026.02.11 |
[석촌] 태양의 토마토 라멘 영업시간 메뉴 후기
영업시간 11:00–21:00
라스트오더 20:30
토마토 라멘이란 접하기 어려운 메뉴
하이디라오에서 토마토탕을 접하고
좋아하지 않았지만 토마토 맛을 알게 되었다.


잠실 롯데타워가 보이는 쪽에서 우측이 입구이다.


올라가는 계단에는
웨이팅을 위한 의자가 준비되어있다.


평일 저녁이라 손님이 없어 내부를 찍었다.
1인 손님을 위한 테이블과
다인원을 위한 테이블이 나눠졌고
매장 안쪽까지 좌석이 많았다.

2월 말까지 키링 증정 이벤트가 있어,
세트 메뉴에서 계란토마토라멘과
농후한토마토크림새우탕멘을 시켰다.
라리조(리조또) 밥도 추가 주문했다.

귀여운 토마토 키링
키캡 키링과 고민하다 토마토 키링
블랙인간으로써 포인트 주기 좋은거 같다.

맛은 계란토마토라멘은
생각한대로 상큰한 토마토 맛이 느껴졌다.
농후한토마토크림새우탕멘은 로제맛과 비슷했다.
새우가 들어있어 새우맛이 강하며,
계란토마토라멘보다 묵직했다.
면도 일본처럼 얇은 면이라,
라멘을 먹는 느낌이였다.
기본찬으로 나오는 단무지는
유자 단무지로,
라멘과 잘 어울렸다.
라리조 (리조또) 는
마지막 라면 국물을 퍼서
밥을 리조또처럼 먹을 수 있다.
천원에 추가가능하며,
마지막까지 토마토 맛을 즐길 수 있었다.
양도 많아 배부르게 먹을 수 있다!
'이모저모 > 식도락' 카테고리의 다른 글
| [수원] 운멜로키친 3호점 후기 (1) | 2026.03.05 |
|---|---|
| [서울/통인시장] 체부동 잔치집 메뉴 후기 (0) | 2026.03.01 |
| [여의도] 최우영스시야 초밥 추천 후기 (0) | 2026.02.26 |
| [모란역] 성남 성원식당 등갈비찜 곤드레밥 영업시간 메뉴 (0) | 2026.02.14 |
| [여의도] 직화 별미볶음집 주차 영업시간 메뉴 내돈내산 (1) | 2026.02.11 |
[모란역] 성남 성원식당 등갈비찜 곤드레밥 영업시간 메뉴
영업시간 11:00-22:00
(라스트 오더 15:30)
브레이크타임 16:00–17:00
월 휴무
모란에 오래된 등갈비찜 식당.
요즘 입소문을 타고 있는 것 같다.
두번째 매장 방문이였는데,
여전히 사람들이 많아 웨이팅을 했다.
아, 주변에 주차할 곳이 없다.
골목길에 있다보니 주차구역을 찾아야 한다.

메뉴는 하나이다.
양푼등갈비 + 곤드레밥
맵기 조절이 가능하다!
참고로 안맵게 시켰다.
진라면 순한맛 먹는 친구는 조금 매콤하게 먹었다고 한다.
불닭 먹는 나로써는 맛있게 먹었다.

기본적으로 메밀전이 나온다!
기본적으로 매콤해서 그런가, 동치미? 도 나온다.
버섯은 추가로 시킨게 아닌
기본적으로 들어있는 양이다!
콩나물은 맛있게 드시는 방법 안내에 따라
끓다가 중간에 넣어야 한다.
처음엔 고기 양이 적은 것 같다 했지만, 많았다.
고기는 야들야들 뼈와 분리가 잘 되어 먹기가 편했다.

먹다보면 나오는 곤드레밥.
하나 시키면 2개로 덜어서 나온다.
받자마자 고소한 참기름향과 곤드레 향이 난다.
열심히 먹느라 추가 사진이 없지만,
성남 사랑 상품권 결제도 된다.

왜 2000원 더 냈지 생각해보니 당면 사리를 추가했다.
PS.
당면 사리 추가해 드세요..
양념이 잘 베여서 메밀전에 싸먹으면 맛있습니다.
'이모저모 > 식도락' 카테고리의 다른 글
| [수원] 운멜로키친 3호점 후기 (1) | 2026.03.05 |
|---|---|
| [서울/통인시장] 체부동 잔치집 메뉴 후기 (0) | 2026.03.01 |
| [여의도] 최우영스시야 초밥 추천 후기 (0) | 2026.02.26 |
| [석촌] 태양의 토마토 라멘 영업시간 메뉴 후기 (0) | 2026.02.23 |
| [여의도] 직화 별미볶음집 주차 영업시간 메뉴 내돈내산 (1) | 2026.02.11 |
오랜만에 블로그 들어와서..
지난 취업 준비하면서 시작한 블로그였는데 취업을 하고 나니 뒷전이 되었다.
20년도 인턴 생활 3개월 끝
정규직 전환과 함께 들여다보지 않았다.
요즘 빠르게 변하는 IT 를 보며,
빠르게 정보를 취득하고 발 빠르게 익혀보는 것이 중요하단 생각이 들었다.
그래서 다시 블로그을 해볼까 한다.
2026.02.11
[여의도] 직화 별미볶음집 주차 영업시간 메뉴 내돈내산
주소 서울특별시 영등포구 국제금융로6길 33 여의도백화점 지하 1층
영업시간 11:00–21:00
브레이크타임 15:00–17:00
토·일 휴무
주차 1,000원 / 1시간 가능
여의도 직장인들에게 유명한 듯한 직화 볶음집.
매번 가보고 싶었었던 식당으로
평일 휴가 겸 여의도 볼 일이 있어 한끼하러 갔다!
참고로,
처음 가는 식당길이라 해맸는데
지하1층 내려가서 지도를 보고 갔는데
매장이 안쪽에 있었다.
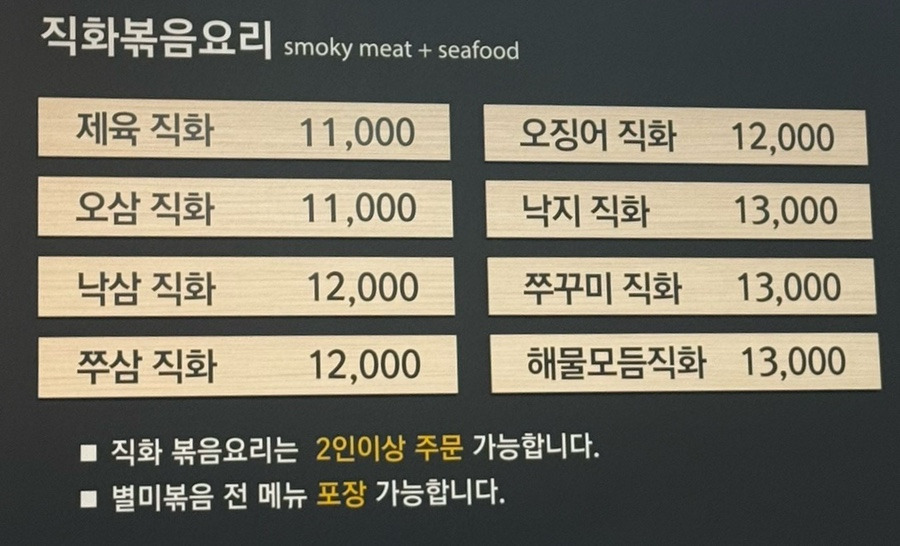

직화 요리는 기본 2인부터 가능
한식 러버로써 공기밥 추가는 무료

비벼 먹을 수 있게 큰 그릇을 주고,
기본 찬으로 미역국, 콩나물, 상추, 김치, 무장아찌가 나온다.

제육볶음 2인분 주문했는데
불향이 확 나고 꽤 매운 편
(불닭 볶음면 좋아하는 사람 기준에서도 매콤)
처음엔 괜찮다가 점점 매워지고
양념이 강한 편이라 계란찜을 추가로 시켰다.

7000원 비싸다 생각했는데 양보고 괜찮아졌다...
계란찜은 양도 많고 매운맛 잡아줘서
같이 먹기 딱 좋았다.
매운 거 잘 못 먹는 사람은
계란찜 꼭 같이 시키는 걸 추천.
불맛 나는 직화 볶음 좋아하면 한 번쯤 가볼 만한 곳.
'이모저모 > 식도락' 카테고리의 다른 글
| [수원] 운멜로키친 3호점 후기 (1) | 2026.03.05 |
|---|---|
| [서울/통인시장] 체부동 잔치집 메뉴 후기 (0) | 2026.03.01 |
| [여의도] 최우영스시야 초밥 추천 후기 (0) | 2026.02.26 |
| [석촌] 태양의 토마토 라멘 영업시간 메뉴 후기 (0) | 2026.02.23 |
| [모란역] 성남 성원식당 등갈비찜 곤드레밥 영업시간 메뉴 (0) | 2026.02.14 |
[Python] 비지도 학습 - 군집분석
[K-Means Clustering]
* 이 알고리즘은 비지도 학습의 가장 간단하면서 널리 사용하는 군집 기법이다.
[과정]
-
- 데이터의 특정 영역을 대표하는 클러스터 중심(cluster center)를 찾는다.
-
- 데이터 포인트를 가장 가까운 클러스터 중심에 할당하고,
-
- 새로 할당된 포인트를 포함한 평균값으로 클러스터 중심을 다시 지정.
-
- 클러스터에 할당되는 데이터 포인트에 변화가 없을 때 알고리즘 종료.
[단점]
-
계산 및 사용이 간단하여 널리 쓰이나, 클러스터의 개수를 지정해야 하므로, 선택에 어려움이 있을 수 있다.
--> 어느정도 데이터의 갯수에 대해 짐작하고 있어야 한다. 그래야 군집을 몇 개 넣을지 알 수 있음.
※ 시각화를 사용해서 데이터를 짐작할 수 있다. (PCA)
- 참고 : 클러스터링(Clustering)은 주어진 데이터 집합을 유사한 데이터들의 그룹으로 나누는 것이며, 예측 문제와 달리 특정한 독립변수와 종속변수의 구분도 없고, 학습을 위한 목표값도 필요로 하지 않는 비지도 학습이다.
from sklearn import datasets
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
import numpy as np
from sklearn.model_selection import train_test_split
import seaborn as sns
## 1. make_blobs toy data
X, y = datasets.make_blobs(random_state = 1)
kmeans = KMeans(n_clusters = 3) # 3개의 클래스를 나타내는 데이터를 만들어 줌.
kmeans.fit(X)
## 2. checking labels
kmeans.labels_
## 3. X predict
kmeans.predict(X)
## 4. scatter graph
%matplotlib inline
plt.scatter(X[:,0], X[:,1],
c = kmeans.labels_, marker = 'o', s = 10)
plt.scatter(kmeans.cluster_centers_[:,0],
kmeans.cluster_centers_[:,1],
c = ['r', 'k', 'b'], marker = '^', s = 50)
plt.show()
## k = 5
kmeans5 = KMeans(n_clusters = 5) # 5개의 클래스를 나타내는 데이터를 만들어 줌.
kmeans5.fit(X)
assign = kmeans5.labels_
# 시각화
%matplotlib inline
plt.scatter(X[:,0], X[:,1],
c = assign, marker = 'o', s = 10)
plt.scatter(kmeans5.cluster_centers_[:,0],
kmeans5.cluster_centers_[:,1],
c = ['r', 'k', 'b', 'gray', 'orange'], marker = '^', s = 50)
plt.show()


- K 의 값을 변경했을 때 결과는 위의 그래프와 같다. 여기서 적합한 k의 값을 찾기 위해서는 PCA를 사용하여 데이터의 형태가 어떻게 되어 있는지 판단하고 군집화 진행하는 것을 추천
[병합 군집]
- 시작할 때, 각각의 포인트 하나하나가 클러스터로 지정됨
- 종료 조건을 만족할 때까지 가장 비슷한 두 클러스터를 합쳐 나간다.
- 사이킷런의 종료 조건은 클러스터 개수
- linkage옵션에서 가장 비슷한 클러스터를 측정하는 방법 지정
- ward: 기본값인 ward연결은 클로스터의 분산을 가장 작게 증가시키는 두 클러스터를 합침
- average: 클러스터 포인트 사이의 평균 거리가 가장 짧은 두 클러스터 병합
- complete: 클러스터 포인트 사이의 최대 거리가 가장 짧은 두 클러스터 병합
- 계층적 클러스터링 : 군집 하나의 데이터 샘플을 하나의 클러스터로 보고 가장 유사도가 높은 클러스터를 합치면서 클러스터 갯수를 줄여 가는 방법을 말한다.
1. Agglomerative Clustering : scikit-learn 패키지
from sklearn.cluster import AgglomerativeClustering
from sklearn import datasets
import matplotlib.pyplot as plt
X, y = datasets.make_blobs(random_state = 1)
agg = AgglomerativeClustering(n_clusters = 3)
assign = agg.fit_predict(X)
%matplotlib inline
fig, ax = plt.subplots()
scatter = ax.scatter(X[:,0], X[:,1],
c = assign, marker="o", s=10)
ax.legend(*scatter.legend_elements(),
loc = 'lower right', title = 'classes')
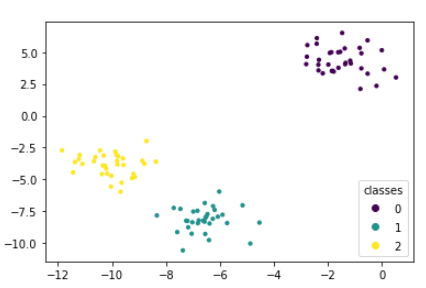
2. 덴드로그램(dendrogram) 사용 : SciPy 패키지 -> 결과를 시각화 해줌
from scipy.cluster.hierarchy import dendrogram, ward
import seaborn as sns
X,y = datasets.make_blobs(random_state=0, n_samples=12)
linkage_array = ward(X) # 분산을 최소화하는 방향으로 클러스터 함
dendrogram(linkage_array) # 위계를 가지는 형태로 만들어줌
ax = plt.gca()
bounds = ax.get_xbound()
ax.plot(bounds, [7.25, 7.25], '--', c='k')
ax.plot(bounds, [4, 4], '--', c='k')
ax.text(bounds[1], 7.25, 'two clusters', va='center', fontdict={'size':15})
ax.text(bounds[1], 4, 'three clusters', va='center', fontdict={'size':15})
plt.xlabel('sample No.')
plt.ylabel('cluster distance')
[DBSCAN]
- density-based spatial clustering of applications with nois
- 클러스터의 개수를 미리 정할 필요가 없음
- 복잡한 형상도 찾을 수 있으며, 어떤 클래스에도 속하지 않는 포인트를 비교적 잘 구분해낸다
- 병합군집, k-mean 보다는 느림
<방법>
- 특성 공간에서 가까이 있는 데이터가 많은, 밀도가 높은 지역의 포인트를 찾음
- 데이터 밀집 지역이 한 클러스터를 구성하며, 비교적 비어 있는 지역을 경계로 다른 클러스터와 구분된다는 아이디어
- min_sample, eps 2개의 매개변수
- 한 데이터 포인트에서 eps 거리 안에 데이터가 min_samples 만큼 있으면, 이 데이터 포인트를 핵심 샘플로 분류
- eps 거리 안에 min_samples보다 데이터가 적으면 잡음으로 분류
- 시작할 때는 모자이크 포인트 선택
from sklearn.cluster import DBSCAN
from sklearn import datasets
import matplotlib.pyplot as plt
X,y = datasets.make_blobs(random_state=0, n_samples=12)
dbscan = DBSCAN()
clusters = dbscan.fit_predict(X)
print("cluster label:{}".format(clusters))
# output : cluster label:[-1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1]
# 해석 : 전부다 잡음이다 클러스터로 분류되지 않았다. 군집으로 분류되지 않았다.
# 그래프 확인(defualt)
%matplotlib inline
plt.scatter(X[:,0],X[:,1],c=clusters, marker = 'o',s=10)
dbscan1 = DBSCAN(min_samples=2, eps=2)
clusters1 = dbscan1.fit_predict(X)
print("cluster label:{}".format(clusters1))
# output : cluster label:[0 1 1 1 1 0 0 0 1 0 0 0]
# 해석 : 0으로 바뀐 두개가 군집화가 된 것을 확인 할 수 있음
# 그래프 확인(min_samples=2, eps=2)
%matplotlib inline
plt.scatter(X[:,0],X[:,1],c=clusters2, marker = 'o',s=10)

- 위 두개의 그래프를 확인해보면 default 그래프보다 매개변수를 조절한 그래프에서 군집화가 발생했다.
- min_sample의 수를 줄이, eps(거리)를 늘린 결과라고 생각하면 된다.
지금까지 본 군집방식에 있어 눈으로 확인하기 위해 다음을 시도해보았다.
from sklearn.metrics.cluster import adjusted_rand_score
from sklearn.preprocessing import StandardScaler
import numpy as np
X, y = datasets.make_moons(n_samples=200, noise = 0.05, random_state=0) # 초승달 데이터 -> 그래프가 초승달로 나옴
# 평균이 0, 분산이 1이 되도록 표준화
scaler = StandardScaler()
scaler.fit(X)
X_scaled = scaler.transform(X)
fig, axes = plt.subplots(1,4,figsize=(15,3),
subplot_kw={'xticks':(), 'yticks':()})
# 사용할 알고리즘 모델의 리스트 작성
algorithms = [KMeans(n_clusters=2), AgglomerativeClustering(n_clusters=2),
DBSCAN()]
# randomly assign에서 ARI=0인 그래프 작성 위해 무작위 클러스터 생성
random_state = np.random.RandomState(seed=0) # 랜덤넘버 생성기인 랜덤함수들을 포함하는 클래스
random_clusters = random_state.randint(low=0,high=2,size=len(X)) # 0 부터 2사이의 무작이 난수 생성
# 위에서 생성한 무작위 클러스터 plotting
axes[0].scatter(X_scaled[:,0],X_scaled[:,1], c=random_clusters, s=60, edgecolors = 'b')
axes[0].set_title("randomly assign - ARI: {:.2f}".format(adjusted_rand_score(y, random_clusters)))
# 3가지 군집 알고리즘 적용한 결과 plotting
for ax, algorithm in zip(axes[1:], algorithms):
clusters = algorithm.fit_predict(X_scaled)
ax.scatter(X_scaled[:,0], X_scaled[:,1], c=clusters,
s=60, edgecolors = 'b')
ax.set_title("{} - ARI: {:.2f}".format(algorithm.__class__.__name__,
adjusted_rand_score(y,clusters)))
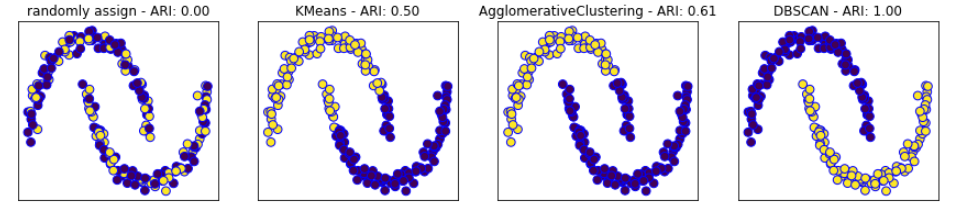
- 그래프를 확인하면 DBSCAN 이 가장 잘 군집화 한 것이라고 생각할 수 있다. 하지만 더 확실하게 하기 위해서는 평가지표를 통한 확인이 필요하다. 이것은 다음 장에서 설명하겠습니다.
'Code > 머신러닝 in Python' 카테고리의 다른 글
| [Python] openCV 이용한 얼굴인식 (0) | 2019.09.03 |
|---|---|
| [Python] PCA(주성분 분석) (0) | 2019.09.03 |
| [Python] Cross-validation + Grid Search (1) | 2019.08.30 |
| [Python] Grid Search (0) | 2019.08.30 |
| [Python] Cross-validation(교차검증) (1) | 2019.08.30 |
[Python] openCV 이용한 얼굴인식
OpenCV(Open Source Computer Vision)
- 인텔에서 만든 강력한 영상처리 라이브러리
- 실시간 이미지 프로세싱에 중점을 둔 라이브러리
- OpenCV-python : OpenCV의 파이썬 API를 모아둔 것
- 아나콘다를 사용하시는 분들은 프롬프트를 열어서 다음 명령어로 설치하시길 바랍니다.
pip install tensorflow
conda update wrapt
pip install keras
pip install opencv-python
- OpenCV를 이용한 간단한 얼굴 인식
import cv2
import sys
# 불러올 경로 결정
image_file = "./image/red.jpg"
cascade_file = "C:/Anaconda3/Lib/site-packages/cv2/data/haarcascade_frontalface_default.xml" # 정면 얼굴인식
cascade_file2 = "C:/Anaconda3/Lib/site-packages/cv2/data/haarcascade_lefteye_2splits.xml"
image = cv2.imread(image_file)
image_gs = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
cascade = cv2.CascadeClassifier(cascade_file)
face_list = cascade.detectMultiScale(image_gs,scaleFactor = 1.1,minNeighbors=3, minSize=(70,70))
cascade2 = cv2.CascadeClassifier(cascade_file2)
eye_list = cascade2.detectMultiScale(image_gs,scaleFactor = 1.1, minNeighbors=1,minSize=(10,10))
if len(face_list) > 0:
print(face_list)
color = [(0,0,255),(0,255,0)]
for face in face_list:
x,y,w,h = face
cv2.rectangle(image, (x,y), (x+w, y+h), color[0], thickness=8)
# 이미지, 가로,세로 시작 위치, 끝나는 위치, 컬러, 선의 굵기
if len(eye_list) > 0:
print(eye_list)
for eye in eye_list:
x,y,w,h = eye
cv2.rectangle(image, (x,y), (x+w, y+h), color[1], thickness=8)
cv2.imwrite("facedetect-output.PNG", image)
else:
print("no face")- 아나콘다에서 openCV가 정상적으로 설치되었을 경우 위와 같은 파일경로에 파일이 있는 것을 확인할 수 있습니다.
- 이미지를 사용자에 따라 저장한 위치에서 불러오고 cascade를 통해 어떤 것을 분류할 것인지 결정합니다.
- minNeighbors : 각 후보 사각형을 유지해야하는 이웃 수를 지정
- minsize : 가능한 최소 객체 크기
- facedetect-output.PNG

- 저는 레드벨벳 얼굴로 테스트를 해보았고 완전히 찾아내지는 못했지만 어느정도 인식하는 것으로 확인 할 수 있었습니다.
# 각각 xml 설명
[정면 얼굴 검출]
arcascade_frontalface_default.xml
haarcascade_frontalface_alt.xml
haarcascade_frontalface_alt2.xml
haarcascade_frontalface_alt_tree.xml
[측면 얼굴 검출]
haarcascade_profileface.xml
[웃음 검출]
haarcascade_smile.xml
[눈 검출]
haarcascade_eye.xml
haarcascade_eye_tree_eyeglasses.xml
haarcascade_lefteye_2splits.xml
haarcascade_righteye_2splits.xml
[고양이 얼굴 검출]
haarcascade_frontalcatface.xml
haarcascade_frontalcatface_extended.xml
[사람의 전신 검출]
haarcascade_fullbody.xml
[사람의 상반신 검출]
haarcascade_upperbody.xml
[사람의 하반신 검출]
haarcascade_lowerbody.xml
[러시아 자동차 번호판 검출]
haarcascade_russian_plate_number.xml
haarcascade_licence_plate_rus_16stages.xml
'Code > 머신러닝 in Python' 카테고리의 다른 글
| [Python] 비지도 학습 - 군집분석 (0) | 2019.09.04 |
|---|---|
| [Python] PCA(주성분 분석) (0) | 2019.09.03 |
| [Python] Cross-validation + Grid Search (1) | 2019.08.30 |
| [Python] Grid Search (0) | 2019.08.30 |
| [Python] Cross-validation(교차검증) (1) | 2019.08.30 |